Wafer は推論システム向けに AI Agent 駆動の最適化を提供します。GPU スタック全体を分析して性能を改善し、ボトルネック特定と高性能サービングの実装を加速します。
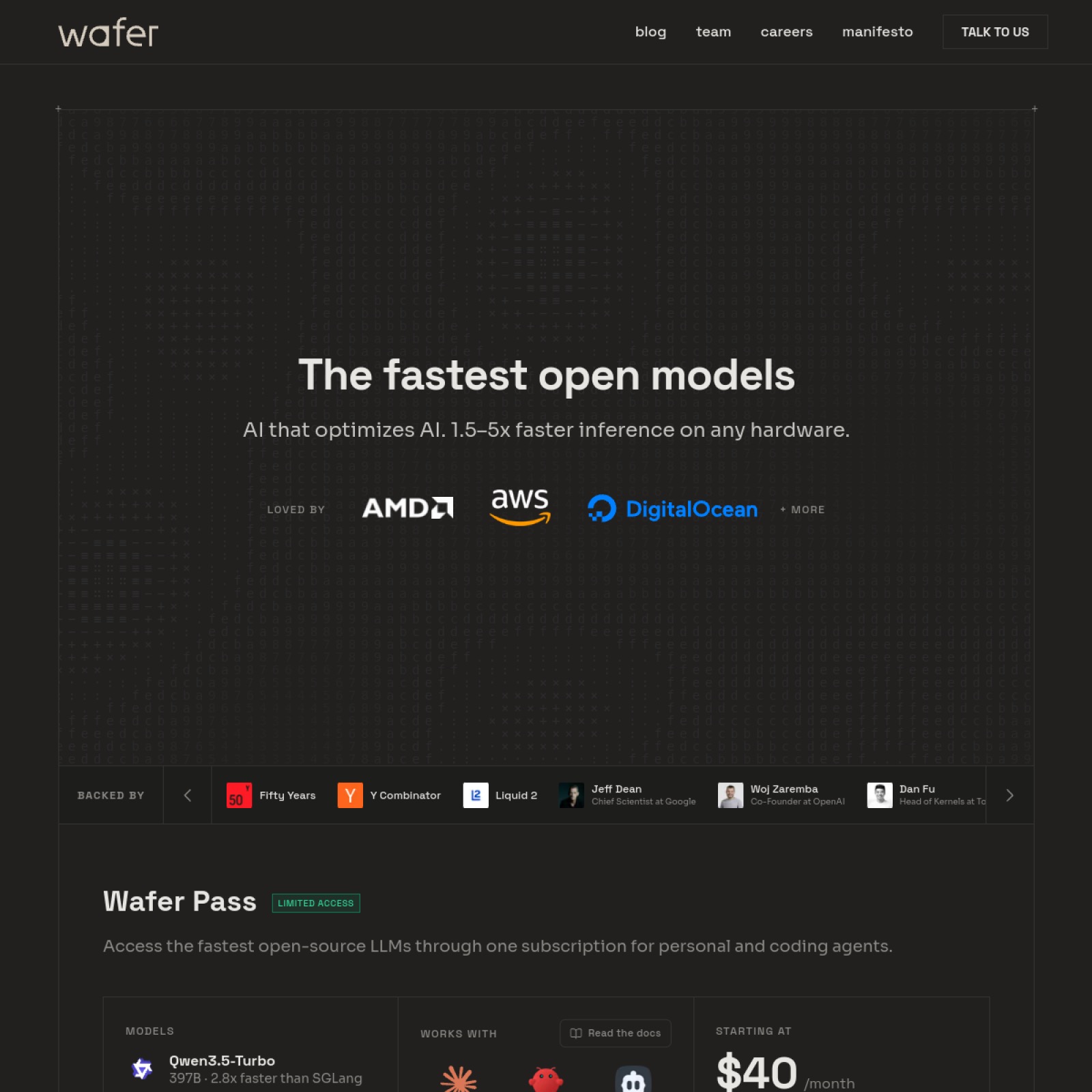
主な機能
- AI エージェント駆動の推論診断
- カーネルからモデルまでのフルスタックの最適化
- GPU 推論のスループットと遅延の向上
- ボトルネック パスの迅速な特定
- エンジニアリング チームの継続的な最適化ワークフローに適合
- 本番環境の推論展開用に構築
ユースケース
- 発売前のパフォーマンス テストとチューニング
- オンライン推論サービスのコスト管理
- 高同時実行時のレイテンシの最適化
- GPU リソース使用率の向上
- 推論プラットフォーム チームの生産性の向上
- LLM およびマルチモデル システムのパフォーマンス チューニング
FAQ
Wafer は推論システム向けに AI Agent 駆動の最適化を提供します。GPU スタック全体を分析して性能を改善し、ボトルネック特定と高性能サービングの実装を加速します。
主な利用シーン: 発売前のパフォーマンス テストとチューニング、オンライン推論サービスのコスト管理、高同時実行時のレイテンシの最適化。