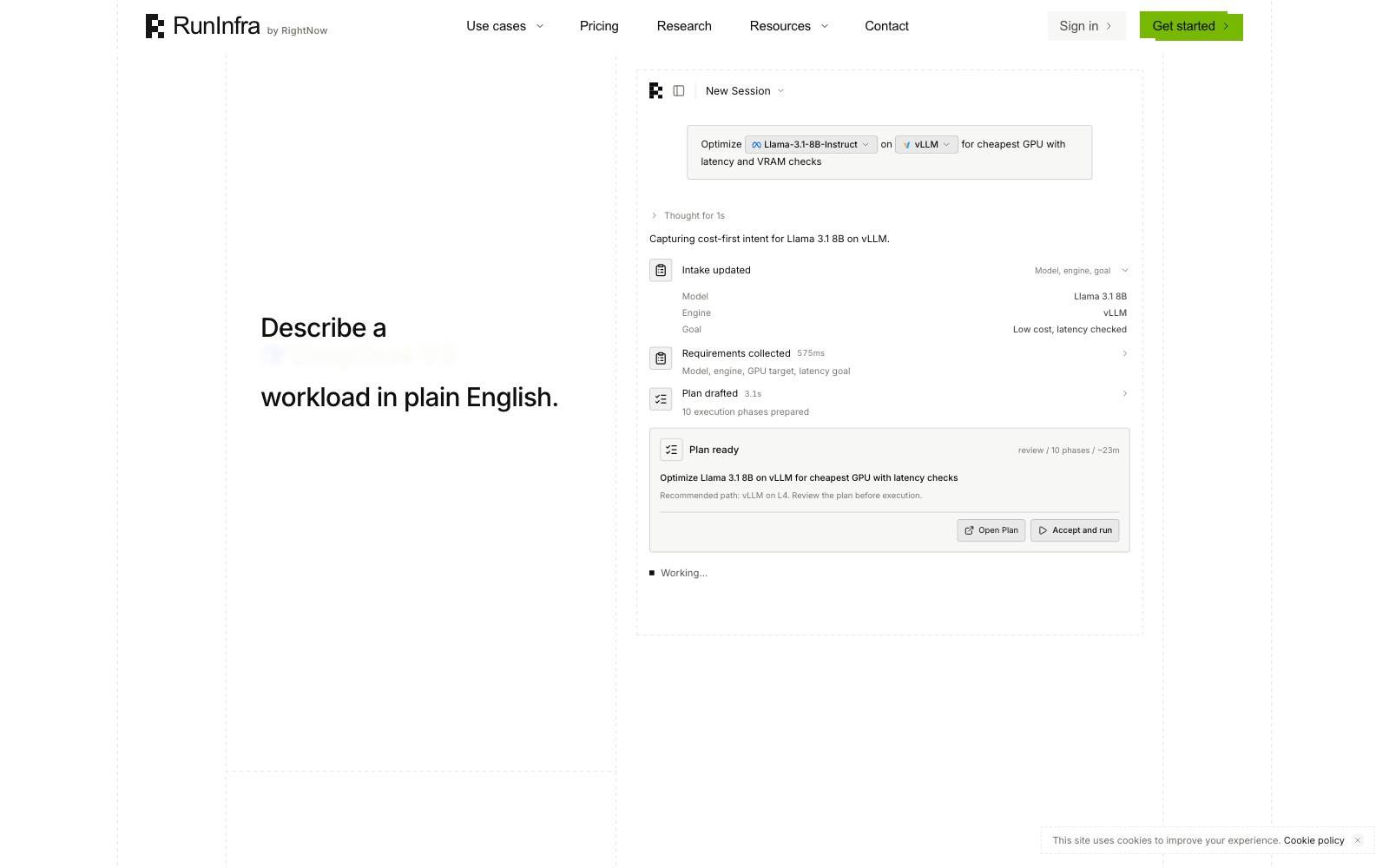
RunInfra permet aux développeurs de décrire un modèle open source ou une application d'IA complète dans le chat, puis de produire une API de production. Il optimise la vitesse et les coûts grâce à l'analyse comparative des GPU, à la quantification des modèles et aux noyaux CUDA personnalisés générés par son agent Forge, avec des options de déploiement gérées ou propres au GPU.
Fonctionnalités
- Déploiement de modèles en langage naturel
- Génération d'API de production
- GPU
- Quantification du modèle
- Noyaux CUDA personnalisés
- Exécution gérée ou propre GPU
Cas d'usage
- Hébergement de modèles open source
- API d'inférence à moindre coût
- Applications voix/document/vision
- Routage du modèle
- Optimisation des ressources GPU
- Production de l'application IA
FAQ
RunInfra permet aux développeurs de décrire un modèle open source ou une application d'IA complète dans le chat, puis de produire une API de production. Il optimise la vitesse et les coûts grâce à l'analyse comparative des GPU, à la quantification des modèles et aux noyaux CUDA personnalisés générés par son agent Forge, avec des options de déploiement gérées ou propres au GPU.
Cas d'usage courants : Hébergement de modèles open source, API d'inférence à moindre coût, Applications voix/document/vision.