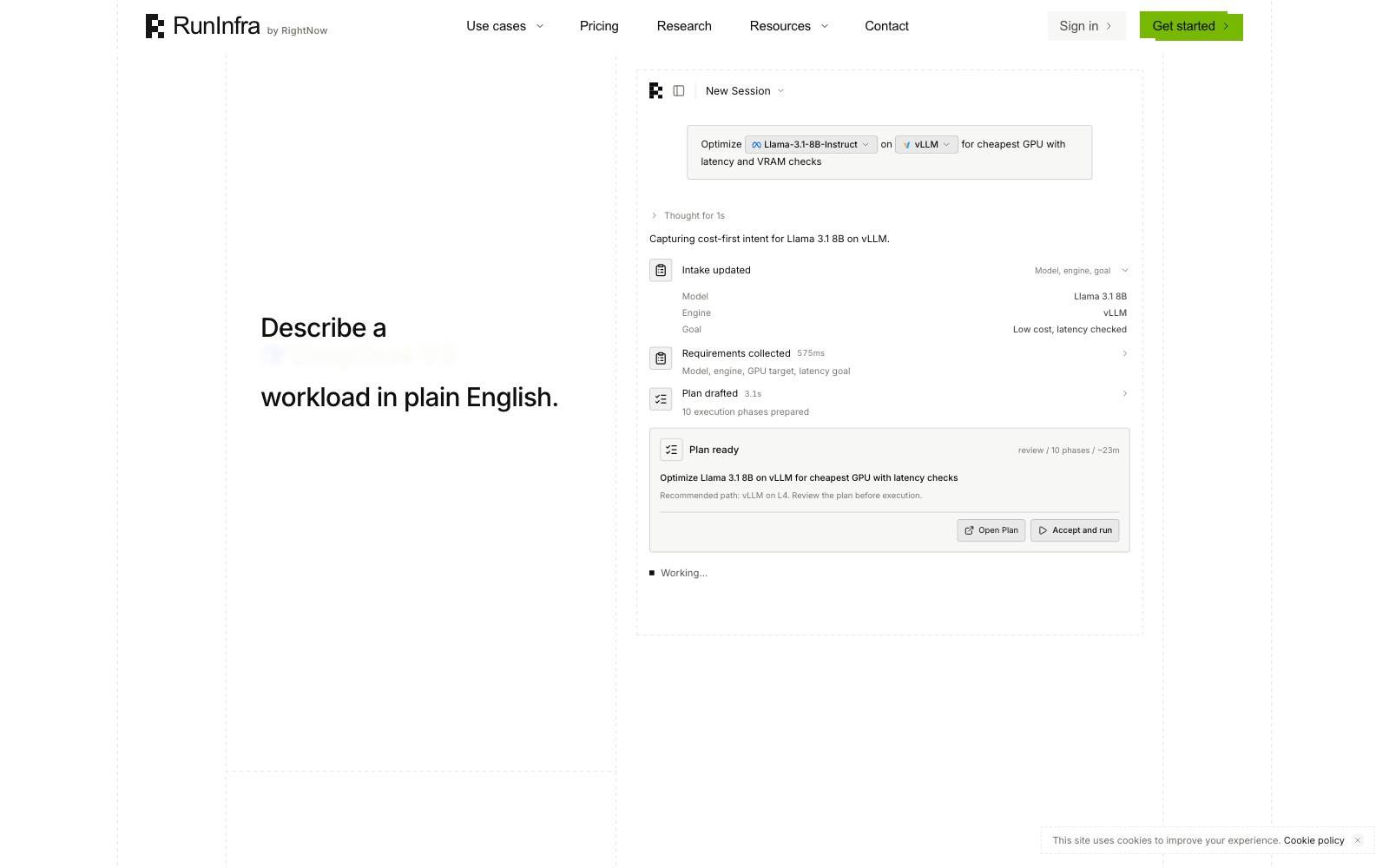
RunInfra lets developers describe an open-source model or full AI app in chat, then produces a production API. It optimizes speed and cost through GPU benchmarking, model quantization, and custom CUDA kernels generated by its Forge agent, with managed or own-GPU deployment options.
Features
- Natural-language model deployment
- Production API generation
- GPU benchmarking
- Model quantization
- Custom CUDA kernels
- Managed or own-GPU runtime
Use Cases
- Open-source model hosting
- Lower-cost inference APIs
- Voice/document/vision apps
- Model routing
- GPU resource optimization
- AI app productionization
FAQ
RunInfra lets developers describe an open-source model or full AI app in chat, then produces a production API. It optimizes speed and cost through GPU benchmarking, model quantization, and custom CUDA kernels generated by its Forge agent, with managed or own-GPU deployment options. Core capabilities include: Natural-language model deployment, Production API generation, GPU benchmarking.
Common scenarios include: Open-source model hosting, Lower-cost inference APIs, Voice/document/vision apps.